上一篇博客btcd源码解析——peer节点之间的区块数据同步(2)——headersFirstMode模式介绍了headersFirstMode模式下,peer节点之间的数据同步过程。本篇博客将介绍非headersFirstMode模式下的数据同步过程。 因为本篇博客中的许多函数都已经在上一篇博客中进行了讲解,且在此不会过多赘述,强烈建议读者在阅读完上一篇博客之后再来阅读本篇博客。
I. 非headersFirstMode模式下的数据同步过程
总的来说,非headersFirstMode模式下的数据同步可分为以下六步,如下图所示: 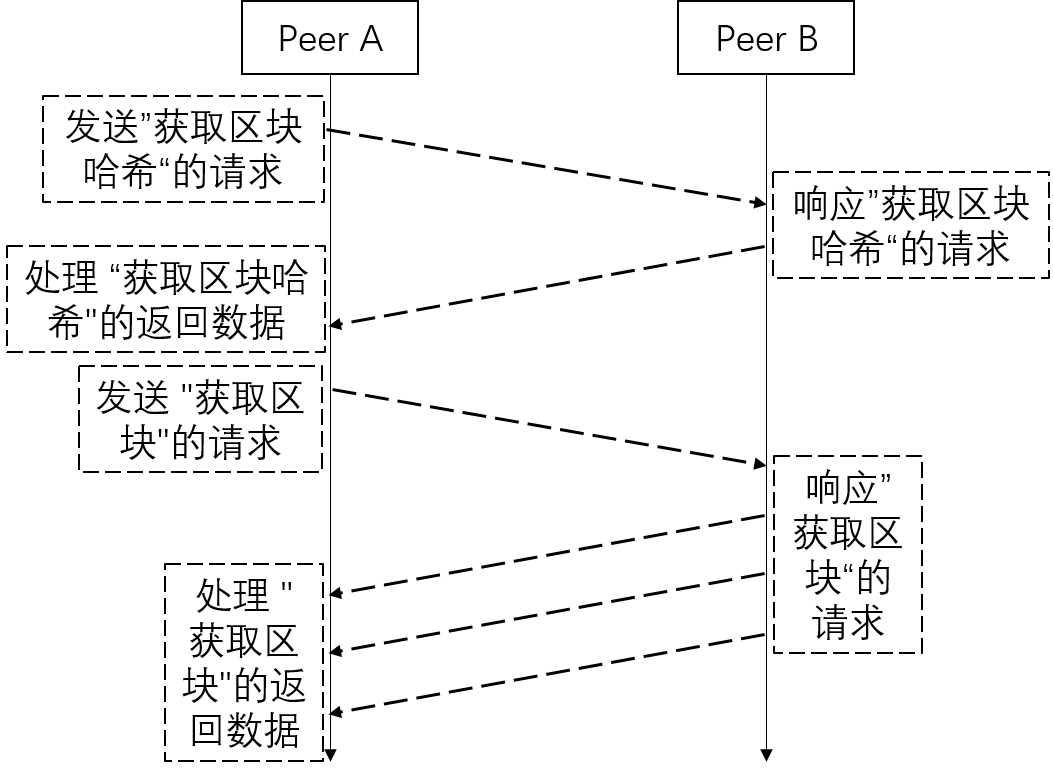
 对比上一篇博客,容易发现两种模式的大致流程是相同的。
对比上一篇博客,容易发现两种模式的大致流程是相同的。
A. peer A 发送“获取区块哈希”的请求
回顾我们在博客btcd源码解析——peer节点之间的区块数据同步 (1)中提及的startSync函数。我们将相关的代码贴在下面: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22// startSync [manager.go]
func (sm *SyncManager) startSync() {
...
if bestPeer != nil {
...
locator, err := sm.chain.LatestBlockLocator()
...
if sm.nextCheckpoint != nil &&
best.Height < sm.nextCheckpoint.Height &&
sm.chainParams != &chaincfg.RegressionNetParams {
bestPeer.PushGetHeadersMsg(locator, sm.nextCheckpoint.Hash) // L338
sm.headersFirstMode = true // L339
...
} else {
bestPeer.PushGetBlocksMsg(locator, &zeroHash) // L344
}
sm.syncPeer = bestPeer
} else {
...
}
}headersFirstMode模式下的数据同步,L344行代码引入了本篇博客的内容——非headersFirstMode模式下的数据同步。对比L344行和L338行代码,容易发现,非headersFirstMode模式直接请求下载block数据。需要注意的是,这里的函数名和变量名很容易让人误解,尽管函数名和变量名中都暗示是获取的区块数据,但其实获取到的是区块的hash,这一点也可以在下一节中看出。 L344行调用的PushGetBlocksMsg函数代码如下所示: 1
2
3
4
5
6
7
8
9
10
11
12
13// startSync [manager.go] -> PushGetBlocksMsg [peer.go]
func (p *Peer) PushGetBlocksMsg(locator blockchain.BlockLocator, stopHash *chainhash.Hash) error {
...
msg := wire.NewMsgGetBlocks(stopHash) // L873
for _, hash := range locator { // L874
err := msg.AddBlockLocatorHash(hash) // L875
if err != nil {
return err
}
} // L879
p.QueueMessage(msg, nil) // L880
...
}MsgGetBlocks变量 (msg),该变量承载了用于发送到peer B的数据。 L874-L879行将locator中的每一个hash加入到msg中的BlockLocatorHashes字段中,其中locator变量我们也已经在上一篇博客中进行了讲解,这里不再赘述。 L880行将该msg通过QueueMessage函数发送出去,QueueMessage函数也已经在上一篇博客的I.A小节进行了讲述,其一步步经过QueueMessageWithEncoding函数, outputQueue管道, queuePacket函数, sendQueue管道, writeMessage函数, 最终在WriteMessageWithEncodingN函数中将数据发送出去。 与上一篇博客的I.A小节不同的是,在当前场景下,WriteMessageWithEncodingN函数中消息头hdr的command被赋值为CmdGetBlocks,因为当前的msg是一个MsgGetBlocks类型的变量。
B. peer B 响应“获取区块哈希”的请求
和上一篇博客的I.B小节类似,作为P2P连接中数据的响应端,peer B运行了一个inHandler协程,用于接收其他peer发来的消息,该inHandler协程在Peer.start函数中启动,启动代码如下所示: 1
2
3
4
5
6
7
8// start [peer.go]
func (p *Peer) start() error {
...
go p.inHandler()
go p.queueHandler()
go p.outHandler()
...
}inHandler函数代码如下所示: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20 // start [peer.go] -> inHandler
func (p *Peer) inHandler() {
...
out:
for atomic.LoadInt32(&p.disconnect) == 0 {
...
rmsg, buf, err := p.readMessage(p.wireEncoding) // L1334
...
switch msg := rmsg.(type) {
...
case *wire.MsgGetBlocks: // L1457
if p.cfg.Listeners.OnGetBlocks != nil {
p.cfg.Listeners.OnGetBlocks(p, msg) // L1459
}
...
}
...
}
...
}readMessage函数从peer连接中读取数据,该函数进一步调用ReadMessageWithEncodingN函数。ReadMessageWithEncodingN函数的代码如下: 1
2
3
4
5
6
7
8
9
10
11
12// start [peer.go] -> inHandler -> readMessage ->
// ReadMessageWithEncodingN [message.go]
func ReadMessageWithEncodingN(r io.Reader, ...) (...) {
...
n, hdr, err := readMessageHeader(r)
...
command := hdr.command // L363
...
msg, err := makeEmptyMessage(command) // L371
...
return totalBytes, msg, payload, nil
}CmdGetBlocks;相应地,L371行生成的msg将是MsgGetBlocks类型。 回到inHandler函数中,L1457行的case被执行,并调用L1459行的OnGetBlocks行数,该函数被赋值为serverPeer.OnGetBlocks,函数定义如下: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18// start [peer.go] -> inHandler -> OnGetBlocks [server.go]
func (sp *serverPeer) OnGetBlocks(_ *peer.Peer, msg *wire.MsgGetBlocks) {
...
chain := sp.server.chain
hashList := chain.LocateBlocks(msg.BlockLocatorHashes, &msg.HashStop,
wire.MaxBlocksPerMsg) // L744
...
invMsg := wire.NewMsgInv() // L747
for i := range hashList { // L748
iv := wire.NewInvVect(wire.InvTypeBlock, &hashList[i]) // L749
invMsg.AddInvVect(iv) // L750
} // L751
...
if len(invMsg.InvList) > 0 {
...
sp.QueueMessage(invMsg, nil) // L764
}
}BlockLocatorHashes和HashStop字段返回相应区块的hash,赋值给hashList变量。 L747行新建了一个MsgInv类型的变量 (invMsg),该变量用于承载响应数据。MsgInv的定义和上一篇博客I.D小节的MsgGetData类型的定义是一样的,如下所示: 1
2
3
4// MsgInv [msginv.go]
type MsgInv struct {
InvList []*InvVect
}OnGetBlocks函数中,L748-L751行针对hashList中的每一个hash值生成一个InvVect变量,并添加到invMsg变量中。 L764行将invMsg变量通过QueueMessage函数发送给peer A. QueueMessage函数也已经在上一篇博客的I.A小节进行了讲述,其一步步经过QueueMessageWithEncoding函数, outputQueue管道, queuePacket函数, sendQueue管道, writeMessage函数, 最终在WriteMessageWithEncodingN函数中将数据发送出去。 与上一篇博客的I.A小节不同的是,在当前场景下,WriteMessageWithEncodingN函数中消息头hdr的command被赋值为CmdInv,因为当前的msg是一个MsgInv类型的变量。
C. peer A 处理“获取区块哈希”的返回数据,并发送“获取区块”的请求
和上一小节类似,peer A也通过inHandler协程接收其他peer发来的消息。 inHandler函数使用readMessage函数从peer连接中读取数据,该函数进一步调用ReadMessageWithEncodingN函数。 所不同的是,这一次ReadMessageWithEncodingN函数中L363行返回CmdInv;相应地,L371行生成的msg将是MsgInv类型。 因此,Peer.inHandler函数中,L1437行的case得到执行;相应地,OnInv函数得到调用。该函数被赋值为serverPeer.OnInv,函数定义如下所示: 1
2
3
4
5
6// OnInv [server.go]
func (sp *serverPeer) OnInv(_ *peer.Peer, msg *wire.MsgInv) {
...
sp.server.syncManager.QueueInv(msg, sp.Peer) // L613
...
}QueueInv函数对接收到的msg进行处理,QueueInv函数定义如下: 1
2
3
4
5// OnInv [server.go] -> QueueInv [manager.go]
func (sm *SyncManager) QueueInv(inv *wire.MsgInv, peer *peerpkg.Peer) {
...
sm.msgChan <- &invMsg{inv: inv, peer: peer}
}QueneInv函数将inv (msg)通过msgChan管道发送出去,管道的另一端连接着SyncManager.blockHandler函数。该部分我们也已经在上一篇博客中介绍过了,这里我们再回顾一下。SyncManager.blockHandler函数的定义如下所示: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18// OnInv [server.go] -> QueueInv [manager.go] -> blockHandler
func (sm *SyncManager) blockHandler() {
...
out:
for {
select {
case m := <-sm.msgChan:
switch msg := m.(type) {
...
case *invMsg: // L1292
sm.handleInvMsg(msg) // L1293
...
}
...
}
}
...
}case得到执行。相应地,L1293行的handleInvMsg函数得到调用。handleInvMsg函数定义如下所示: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61// OnInv [server.go] -> QueueInv [manager.go] -> blockHandler -> handleInvMsg
func (sm *SyncManager) handleInvMsg(imsg *invMsg) {
...
lastBlock := -1 // L1060
invVects := imsg.inv.InvList
for i := len(invVects) - 1; i >= 0; i-- { // L1062
if invVects[i].Type == wire.InvTypeBlock {
lastBlock = i
break
}
} // L1067
invVects := imsg.inv.InvList
...
for i, iv := range invVects { // L1097
...
if sm.headersFirstMode { // L1113
continue
} // L1115
...
haveInv, err := sm.haveInventory(iv) // L1118
...
if !haveInv {
...
state.requestQueue = append(state.requestQueue, iv) // L1143
continue
}
if iv.Type == wire.InvTypeBlock { // L1147
...
if i == lastBlock { // L1178
...
locator := sm.chain.BlockLocatorFromHash(&iv.Hash)
peer.PushGetBlocksMsg(locator, &zeroHash)
}
} // L1185
} // L1186
...
gdmsg := wire.NewMsgGetData() // L1191
requestQueue := state.requestQueue
for len(requestQueue) != 0 { // L1193
iv := requestQueue[0]
requestQueue[0] = nil
requestQueue = requestQueue[1:]
switch iv.Type {
...
case wire.InvTypeBlock:
...
if _, exists := sm.requestedBlocks[iv.Hash]; !exists {
...
gdmsg.AddInvVect(iv) // L1233
}
}
...
} // L1241
state.requestQueue = requestQueue
if len(gdmsg.InvList) > 0 {
peer.QueueMessage(gdmsg, nil) // L1244
}
}lastBlock变量,该变量记录了imsg中最后一个block的序号(L1062-L1067行进行了变量更新)。 L1093-L1186行对接收到的imsg中的每一个iv进行处理:
- 首先,L1113-L1115行表明如果当前模式是
headersFisrtMode模式,则忽略当前的iv。 - 其次,L1147判断当前iv是否是
InvTypeBlock类型。如果是,则进行后续处理。L1178行判断是否当前inv是imsg中最后一个block的inv,如果是,则继续下一轮的区块获取过程。 - 然后,L1191行定义了一个
MsgGetData类型的变量 (gdmsg), 该变量承载了用于获取区块的请求。MsgGetData数据类型在上一篇博客中也已经介绍过了,这里不再赘述。L1193-L1141行将符合条件的iv添加到gdmsg变量中。 - 最后,L1244行通过
QueueMessage函数将gdmsg变量发送出去。QueueMessage函数也已经在上一篇博客的I.A小节进行了讲述。再啰嗦一遍,其一步步经过QueueMessageWithEncoding函数,outputQueue管道,queuePacket函数, sendQueue管道,writeMessage函数, 最终在WriteMessageWithEncodingN函数中将数据发送出去。
与上一篇博客的I.A小节不同的是,在当前场景下,WriteMessageWithEncodingN函数中消息头hdr的command被赋值为CmdGetData,因为当前的msg是一个MsgGetData类型的变量。
D. peer B 响应“获取区块”的请求
该过程完全和上一篇博客的I.E小节相同,此处不再赘述。
E. peer A 处理“获取区块”的返回数据
该过程完全和上一篇博客的I.F小节相同,此处不再赘述。
II. 小结
至此,我们介绍完了非headersFirstMode模式下节点之间的区块数据同步的过程。
和上一篇博客headersFirstMode模式比较,两种模式在后半部分的处理过程完全一致。前半部分的处理中,非headersFirstMode模式相对来说要简单一些。具体而言,headersFirstMode模式中的peer A在处理第一步请求的返回数据和发起第二步请求较为复杂,我们在上一篇博客中分为了两个小节 (I.C小节和I.D小节)进行讲述;相反,非headersFirstMode模式下peer A在处理第一步请求的返回数据和发起第二步请求时较为简单,我们在本片博客中只用了一个小节 (I.C小节) 进行了讲述。