前两篇博客headersFirstMode模式和非headersFirstMode模式主要介绍了区块数据同步过程中两个节点如何交互。但我们当时遗留下一个问题:在peer A接收到区块数据之后,是如何将这个区块存储到本地的。回忆我们在headersFirstMode模式的I.F小节最后提到的
由于block的数据存储过程比较复杂,我们在后面会再写一篇博客介绍:从P2P连接中接收到的block数据是如何存储的
本篇博客主要就来介绍“区块数据的存储过程”。
I. 区块数据的存储过程
回忆我们在headersFirstMode模式的I.F小节最后提到的blockHandler函数,其代码如下所示: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// inHandler [peer.go] -> OnBlock [server.go] -> QueueBlock [manager.go] -> blockHandler
func (sm *SyncManager) blockHandler() {
...
out:
for {
select {
case m := <-sm.msgChan:
switch msg := m.(type) {
...
case *blockMsg:
sm.handleBlockMsg(msg) // L1289
msg.reply <- struct{}{}
...
}
}
...
}peer A接收到区块数据后,主要在L1289行调用了handleBlockMsg函数来处理该数据。以下就是从handleBlockMsg函数开始介绍区块数据的存储过程。
A. SyncManager数据结构
SyncManager这个类型我们已经见过很多次了,这里我们先来看一下SyncManager类型的定义: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// SyncManager [manager.go]
type SyncManager struct { // L155
...
msgChan chan interface{}
...
requestedBlocks map[chainhash.Hash]struct{}
syncPeer *peerpkg.Peer
peerStates map[*peerpkg.Peer]*peerSyncState
...
headersFirstMode bool
headerList *list.List
startHeader *list.Element
nextCheckpoint *chaincfg.Checkpoint
...
}
- msgchan:我们在前几篇博客中多次提到该字段,该字段主要用于将P2P连接中接收到的数据传递给blockHandler函数进行处理,具体可见博客btcd源码解析(1)的第I小节和btcd源码解析(2)的第I.C小节
- requestedBlocks:该字段主要用于记录哪些区块处于"requested"状态。每次发出一个获取区块的请求前,先将该区块的
hash加入到requestedBlocks中;每次收到区块后,将该区块的hash从requestedBlocks中删除 - syncPeer:该字段主要用于标识该节点(
peer A)正在用于数据同步的peer B. 任何时刻,只存在一个用于同步的syncPeer。每次会选出最佳的peer B赋值给syncPeer(见btcd源码解析(1)的第I小节),且在peer B失去连接等情况发生时,syncPeer会被切换为其他peer - peerStates:该字段主要用于记录所有
peer的同步状态。因为syncPeer会在不同peer之间切换,需要记录下来跟每个peer进行数据同步的状态 - headersFirstMode:该字段表明当前是否采用
headersFirstMode同步模式 - headerList:该字段只在
headersFirstMode模式下有意义。由于在headersFirstMode模式下,headers和blocks都是按阶段下载的。checkpoint将所有的区块分成若干个区间,每个阶段下载其中一个区间的header(block),完成后再下载下一个区间 - startHeader:该字段只在headersFirstMode模式下有意义。
startHeader标识当前正在处理的checkpoint区间中,还未发出block获取请求的第一个header - nextCheckpoint:该字段只在
headersFirstMode模式下有意义。nextCheckpoint标识当前正在处理的checkpoint区间的下边界
B. handleBlockMsg函数分析
handleBlockMsg函数的定义如下所示: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52// inHandler [peer.go] -> OnBlock[server.go]->QueueBlock[manager.go]
// -> blockHandler -> handleBlockMsg
func (sm *SyncManager) handleBlockMsg(bmsg *blockMsg) {
...
isCheckpointBlock := false // L660
behaviorFlags := blockchain.BFNone
if sm.headersFirstMode {
firstNodeEl := sm.headerList.Front()
if firstNodeEl != nil {
firstNode := firstNodeEl.Value.(*headerNode)
if blockHash.IsEqual(firstNode.hash) {
behaviorFlags |= blockchain.BFFastAdd
if firstNode.hash.IsEqual(sm.nextCheckpoint.Hash){
isCheckpointBlock = true
}else{
sm.headerList.Remove(firstNodeEl)
}
}
}
} // L675
...
_, isOrphan, err := sm.chain.ProcessBlock(bmsg.block, behaviorFlags) // L723
...
if !sm.headersFirstMode { // L784
return
} // L786
...
if !isCheckpointBlock { // L791
if sm.startHeader != nil &&
len(state.requestedBlocks) < minInFlightBlocks{
sm.fetchHeaderBlocks()
}
return
} // L797
...
prevHeight := sm.nextCheckpoint.Height // L803
prevHash := sm.nextCheckpoint.Hash
sm.nextCheckpoint = sm.findNextHeaderCheckpoint(prevHeight)
if sm.nextCheckpoint != nil {
locator :=blockchain.BlockLocator([]*chainhash.Hash{prevHash})
err := peer.PushGetHeadersMsg(locator, sm.nextCheckpoint.Hash)
...
return
} // L818
...
sm.headersFirstMode = false // L823
sm.headerList.Init()
...
locator := blockchain.BlockLocator([]*chainhash.Hash{blockHash})
err = peer.PushGetBlocksMsg(locator, &zeroHash) // L827
...
}
- L660-L675: 根据获得的
block数据,对一些变量进行赋值 - L723: 调用
ProcessBlock函数,该函数完成了区块处理最主要的功能,包括:区块数据的验证、处理orphan区块、将区块插入到链中、基于新插入的区块判断是否需要reorganize最长链 - L784-L786: 如果当前是正常的区块下载模式 (
非headersFirstMode模式),直接返回 - L791-L797: 如果当前区块不是
checkpoint区块,且当前区间中仍有未发出block获取请求的区块,且已发出获取请求但未接收到响应的区块个数小于minInFlightBlocks,继续调用fetchHeaderBlocks函数发出新的区块请求。fetchHeaderBlocks函数的定义见博客btcd源码解析(2)的I.D小节。 - L803-L818: 如果当前处于
headersFirstMode模式,且当前区块是checkpoint区块,且存在下一个checkpoint,说明这一个区间的header和block下载已经完成了,可以开始下一个区间的下载了。下一个区间的下载和之前类似,具体流程可参看博客btcd源码解析(2) - L823-L827: 如果当前处于
headersFirstMode模式,且当前区块是checkpoint区块,且不存在下一个checkpoint,则切换到正常的区块下载模式 (非headersFirstMode模式),具体流程可参看博客btcd源码解析(3)
C. ProcessBlock函数分析
这一节,我们重点就来分析一下ProcessBlock函数,该函数定义如下所示: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25// inHandler [peer.go] -> OnBlock [server.go] ->
// QueueBlock [manager.go] -> blockHandler -> handleBlockMsg ->
// ProcessBlock [process.go]
func (b *BlockChain) ProcessBlock(block *btcutil.Block, flags
BehaviorFlags) (bool, bool, error) {
...
err = checkBlockSanity(...) // L168
...
blockHeader := &block.MsgBlock().Header
...
prevHash := &blockHeader.PrevBlock // L214
prevHashExists, err := b.blockExists(prevHash)
...
if !prevHashExists {
...
b.addOrphanBlock(block) // L221
return false, true, nil
} // L224
...
isMainChain, err := b.maybeAcceptBlock(block, flags) // L228
...
err = b.processOrphans(blockHash, flags) // L236
...
return isMainChain, false, nil
}prevHash是否存在。如果不存在,说明该区块是orphan,通过L221行的addOrphanBlock函数,将该block加入到orphans字典中 L228: maybeAcceptBlock函数将block加入到链中,并返回一个bool值标识该block是否在最长链中 L236: processOrphans函数尝试利用该block将之前的orphan串起来。具体而言,如果之前的block正好是因为缺少当前的这个block而被判别为了orphan(因为整个链断开了),那么当当前这个block到来时,便可以将之前的orphan都串起来了。
D. maybeAcceptBlock函数分析
这一节我们来分析一下maybeAcceptBlock函数,该函数定义如下: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21// inHandler [peer.go] -> OnBlock [server.go] -> QueueBlock
// [manager.go] -> blockHandler -> handleBlockMsg -> ProcessBlock
// [process.go] -> maybeAcceptBlock [accept.go]
func (b *BlockChain) maybeAcceptBlock(block *btcutil.Block, flags
BehaviorFlags) (bool, error) {
...
err = b.db.Update(func(dbTx database.Tx) error { // L56
return dbStoreBlock(dbTx, block)
}) // L58
...
blockHeader := &block.MsgBlock().Header // L66
newNode := newBlockNode(blockHeader, prevNode)
newNode.status = statusDataStored
b.index.AddNode(newNode)
err = b.index.flushToDB() // L71
...
isMainChain, err := b.connectBestChain(newNode, block, flags) //L79
...
return isMainChain, nil
}index和node的作用,node可以认为是block的代表,使得block信息的查询更加快捷;index用于保存这些node。L66-L71行代码基于该区块构建了一个node,并将该node加入到index中,最后将该index刷新到数据库中。 L79:通过maybeAcceptBlock的若干检查之后,真正地将block写入到区块链中
E. connectBestChain函数分析
本小节主要分析connectBestChain函数,该函数代码如下所示: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45// inHandler [peer.go] -> OnBlock [server.go] -> QueueBlock
// [manager.go] -> blockHandler -> handleBlockMsg -> ProcessBlock
// [process.go] -> maybeAcceptBlock [accept.go] ->
// connectBestChain[chain.go]
func (b *BlockChain) connectBestChain(node *blockNode, block
*btcutil.Block, flags BehaviorFlags) (bool, error) {
...
parentHash := &block.MsgBlock().Header.PrevBlock
if parentHash.IsEqual(&b.bestChain.Tip().hash) { // L1102
...
view := NewUtxoViewpoint() // L1109
view.SetBestHash(parentHash)
stxos := make([]SpentTxOut, 0, countSpentOutputs(block)) // L1111
if !fastAdd { // L1112
err := b.checkConnectBlock(node, block, view, &stxos) // L1113
...
} // L1132
if fastAdd { // L1133
err := view.fetchInputUtxos(b.db, block) // L1134
...
err = view.connectTransactions(block, &stxos) // L1138
...
} // L1142
...
err := b.connectBlock(node, block, view, stxos) // L1145
...
} // L1170
...
if node.workSum.Cmp(b.bestChain.Tip().workSum) <= 0 { // L1178
...
fork := b.bestChain.FindFork(node) // L1180
if fork.hash.IsEqual(parentHash) { // L1181
...
} else { // L1185
...
} // L1189
return false, nil
} // L1192
...
detachNodes, attachNodes := b.getReorganizeNodes(node) // L1201
...
err := b.reorganizeChain(detachNodes, attachNodes) // L1205
...
}PrevBlock是否是bestChain的tip. 如果是,则表明当前的block延长了main chain. L1102-L1170便是来处理"延长main chain"这种情况的。 具体而言:
- L1109创建了一个
UtxoViewpoint变量 (view)。view主要用来记录某个状态下的utxo的视图 - L1111创建了一个
SpentTxOut的slice(stxos)。stxos主要用来记录当前区块花出去的utxo分两种情况 (headersFirstMode和非headersFirstMode),view和stxos在后续代码中得到了填充。当为非headersFirstMode模式时,view和stxos在L1113行得到了填充;当为headersFirstMode模式时,view在L1134行得到填充,stxos在L1138行得到填充。 以下先来看一下L1113行的checkConnectBlock函数。
1. 非headersFirstMode模式下填充view和stxos变量
1 | // inHandler [peer.go] -> OnBlock [server.go] -> QueueBlock |
L1039行使用fetchInputUtxos函数对view变量进行填充。总体而言,fetchInputUtxos函数主要是将一个block中所有的input所对应的output加入到view变量中。以下先来看一下fetchInputUtxos函数。
1) fetchInputUtxos函数分析
1 | // inHandler [peer.go] -> OnBlock [server.go] -> QueueBlock |
一个block中的input的来源分为两种情况:
input来源于之前block生成的output(第1种情况)input来源于当前block之前transaction生成的output(第2种情况)
fetchInputUtxos函数也主要从这两种情况进行处理。
- L533-L537: 将当前
block中的所有transaction加入到txInFlight变量中,方便后续查找 - L542: 新建了一个
neededSet变量,该变量主要用来记录第一种来源的input对应的OutPoint - L543-L573: 逐个处理每个
非coinbase的transaction。对于每个transaction中的每个input,首先判断该input的来源是哪种情况。若是第2种情况,则基于当前区块中相应的transaction(originalTx),利用AddTxOuts函数构建output并加入到view变量中 (见L556-L563)。若是第一种情况,则将该input对应的OutPoint加入到neededSet变量中 - L576: 基于
neededSet,将OutPoint对应的output加入到view变量中。因为需要从数据库中查询,所以需要传入db参数。
2) connectTransaction函数分析
回到 I.E.1小节的checkConnectBlock函数,L1120行采用connectTransaction函数对view变量进行了更改,并对stxos变量进行了填充。以下是connectTransaction函数的定义: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40// inHandler [peer.go] -> OnBlock [server.go] -> QueueBlock
// [manager.go] -> blockHandler -> handleBlockMsg -> ProcessBlock
// [process.go] -> maybeAcceptBlock [accept.go] -> connectBestChain
// [chain.go] -> checkConnectBlock [validate.go] -> connectTransaction
// [utxoviewpoint.go]
func (view *UtxoViewpoint) connectTransaction(tx *btcutil.Tx,
blockHeight int32, stxos *[]SpentTxOut) error {
...
if IsCoinBase(tx) { // L221
...
view.AddTxOuts(tx, blockHeight)
return nil
} // L225
...
for _, txIn := range tx.MsgTx().TxIn { // L230
...
entry := view.entries[txIn.PreviousOutPoint] // L233
...
if entry == nil {
return AssertError(fmt.Sprintf("view missing input %v",
txIn.PreviousOutPoint))
} // L237
...
if stxos != nil {
// Populate the stxo details using the utxo entry.
var stxo = SpentTxOut{ // L242
Amount: entry.Amount(),
PkScript: entry.PkScript(),
Height: entry.BlockHeight(),
IsCoinBase: entry.IsCoinBase(),
}
*stxos = append(*stxos, stxo) // L248
}
...
entry.Spend() // L254
} // L255
...
view.AddTxOuts(tx, blockHeight) // L258
return nil
}coinbase,则直接将该transaction对应的output加入到view变量中,stxos不变 - L230-L255: 对每一个TxIn进行处理 - L233-L237: 如果某个txIn对应的PreviousOutPoint在view中不存在,说明该input出错无效 - L242-L248: 根据该txIn对应的output构建stxo,并加入到stxos中 - L254: 更新view中该txIn对应的output,利用Spend函数,将其更新为"已花费" - L258: 将该交易中的output加入到变量view中
2. headersFirstMode模式下填充view和stxos变量
回到I.E小节的connectBestChain函数,L1133-L1142行完成了headersFirstMode模式下对view和stxos变量的填充。L1134行的fetchInputUtxos函数,我们已经在I.E.1.1小节进行了讲解,下面看一下L1138行的connectTransactions函数。
1) connectTransactions函数分析
1 | // inHandler [peer.go] -> OnBlock [server.go] -> QueueBlock |
可以看出,connectTransactions只是调用了connectTransaction函数,后者在I.E.1.2小节也已经介绍过,这里不再赘述。
3. connectBlock函数介绍
回到I.E小节的connectBestChain函数,L1145行调用connectBlock函数将block加入到main chain中,后者的函数定义如下所示: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24// inHandler [peer.go] -> OnBlock [server.go] -> QueueBlock
// [manager.go] -> blockHandler -> handleBlockMsg -> ProcessBlock
// [process.go] -> maybeAcceptBlock [accept.go] -> connectBestChain
// [chain.go] -> connectBlock [chain.go]
func (b *BlockChain) connectBlock(...) error {
...
err = b.db.Update(func(dbTx database.Tx) error {
...
err := dbPutBestState(dbTx, state, node.workSum)
...
err = dbPutBlockIndex(dbTx, block.Hash(), node.height)
...
err = dbPutUtxoView(dbTx, view)
...
err = dbPutSpendJournalEntry(dbTx, block.Hash(), stxos)
...
if b.indexManager != nil {
err := b.indexManager.ConnectBlock(dbTx, block, stxos) // L644
...
}
...
})
...
}
connectBlock函数的功能主要是把最新的数据更新到数据库中,包括BestState, BlockIndex, UtxoView和SpendJournalEntry. 值得一提的是L644行的ConnectBlock函数,该函数被赋值为Manager.ConnectBlock. btcd的实现中,为了方便block, transaction, address等元素的查找,实现了若干个index,并保存到数据库中。ConnectBlock函数便是用来更新这些index的。
4. 区块分叉的两种情形
回到I.E小节的connectBestChain函数中,L1178-L1192行处理可能的分叉问题。其中L1181行的分支在当前区块的前一个区块处分叉,所以第一次形成了一条side chain,如下图左图所示;L1185行的分支在已有的side chain上延长,如下图右图所示。 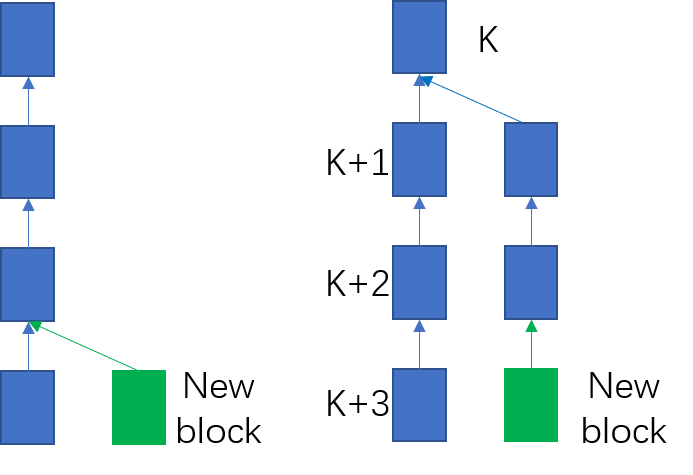
5. reorganizeChain的过程分析
回到I.E小节的connectBestChain函数中。当函数运行到L1202行时,说明新block的加入导致了side chain (分叉链) 的算力超过了main chain,需要用side chain替换现有的main chain,这个过程称为reorganizeChain. 总体而言,reorganizeChain的过程需要将旧的main chain中的block对链的影响进行回滚,并施加新的main chain中的block对链的影响。 由于并不需要将旧链中的所有block进行回滚,只需要回滚分叉点之后的block。如上图右图所示,只需要回滚编号k之后的block. 同理,只需要添加新链中编号k之后的block. L1202行调用getReorganizeNodes函数得到需要回滚的block (detachNodes)和需要添加的block (attachNodes). L1205行基于detachNodes和attachNodes对链的状态进行重新组织。重新组织的过程是调用reorganizeChain函数实现的。reorganizeChain函数主要功能分为两个部分:
- 回滚
detachNodes中区块的操作,可以看作I.E.1或I.E.2小节的逆过程,这里不再赘述 - 添加
attachNodes中的区块,和I.E.1或I.E.2小节类似,这里也不再赘述。
III. 小节
至此,我们介绍完了peer节点之间数据同步过程中的数据到底是怎么存储的。 总体而言,主体的函数调用路径是: > handleBlockMsg -> ProcessBlock [process.go] -> maybeAcceptBlock [accept.go] -> connectBestChain [chain.go] -> connectBlock [chain.go]
数据的存储也包括五个部分:BestState, BlockIndex, UtxoView, SpendJournalEntry和Index.