在开始本篇博客之前,我们首先回顾一下前两篇博客的内容 第一篇博客介绍了比特币签名相关的基础知识,第二篇博客博客介绍了签名的基本原理。本篇博客将从btcd的源码层面分析签名的具体流程。
IV. 签名流程——源码层
源码分析所针对的btcd版本为: ed77733ec07dfc8a513741138419b8d9d3de9d2d 签名流程中message的构建主要是由calcSignatureHash函数实现的,其主体代码如下所示: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67// calcSignatureHash [script.go]
func calcSignatureHash(script []parsedOpcode, hashType SigHashType, tx *wire.MsgTx,
idx int) []byte {
...
if hashType&sigHashMask == SigHashSingle && idx >= len(tx.TxOut) { // L620
var hash chainhash.Hash
hash[0] = 0x01
return hash[:]
}
...
script = removeOpcode(script, OP_CODESEPARATOR) // L627
...
txCopy := shallowCopyTx(tx) // L631
for i := range txCopy.TxIn { // L632
if i == idx { // L633
...
sigScript, _ := unparseScript(script) // L636
txCopy.TxIn[idx].SignatureScript = sigScript // L637
} else {
txCopy.TxIn[i].SignatureScript = nil // L639
}
}
switch hashType & sigHashMask { // L643
case SigHashNone:
txCopy.TxOut = txCopy.TxOut[0:0] // Empty slice. // L645
for i := range txCopy.TxIn { // L646
if i != idx {
txCopy.TxIn[i].Sequence = 0
}
} // L650
case SigHashSingle:
// Resize output array to up to and including requested index.
txCopy.TxOut = txCopy.TxOut[:idx+1] // L654
// All but current output get zeroed out.
for i := 0; i < idx; i++ { // L658
txCopy.TxOut[i].Value = -1
txCopy.TxOut[i].PkScript = nil // L659
}
// Sequence on all other inputs is 0, too.
for i := range txCopy.TxIn { // L663
if i != idx {
txCopy.TxIn[i].Sequence = 0
}
} // L667
default: // L669
// Consensus treats undefined hashtypes like normal SigHashAll
// for purposes of hash generation.
fallthrough
case SigHashOld:
fallthrough
case SigHashAll:
// Nothing special here. // L677
}
if hashType&SigHashAnyOneCanPay != 0 { // L678
txCopy.TxIn = txCopy.TxIn[idx : idx+1]
} // L680
...
wbuf := bytes.NewBuffer(make([]byte, 0, txCopy.SerializeSizeStripped()+4)) // L685
txCopy.SerializeNoWitness(wbuf)
binary.Write(wbuf, binary.LittleEndian, hashType)
return chainhash.DoubleHashB(wbuf.Bytes()) // L688
}calcSignatureHash中的关键部分进行分析。
A. 特殊情况的处理
L620行首先对特殊情况进行处理,即:采用了SigHashSingle类型 (不管是有修饰类还是无修饰类),但input的索引值(index)大于TxNew中的output数目。为什么说这种情况是一种特殊情况呢? 回顾上篇博客 III.A.3节的内容。在SigHashSingle的签名类型下,message需要包含对应当前input索引值的output。因此,当input的索引值大于TxNew中的output数目的时候,便出现了特殊情况。 在这种特殊情况下,简单地返回0x010000...0000 (共一个01,31个00)的字节切片。
B. 删除OP_CODESEPARATOR操作码
L627行通过调用removeOpcode函数,将script中的OP_CODESEPARATOR操作码全部删除。 这对应于上篇博客图2中的黄色框部分。
C. input部分的通用处理
L631行至L641行,对input部分进行了通用的处理。对应于上篇博客中III.A小节的内容:
- 在后面的内容中,我们都是以第一个
input(vin[0])为例进行介绍,其他input也是同理。- 签名部分填充在
vin[0]的的scriptSigLen和scriptSig中,也即图中红色框中。- 对于
vin[0]而言,签名之前scriptSigLen和scriptSig中是没有内容的。其借助于vout[0]中的scriptPubkey进行填充。具体而言,将vout[0]中的scriptPubkey去除OP_CODESEP操作码后,将其内容和长度分别填充到scriptSig和scriptSigLen中。如图2中黄色框所示。- 对于其他
input(如vin[1])而言,scriptSigLen和scriptSig分别填充为0值和空值,如图2中暗绿色框所示。
为方便读者阅读,我们将相应的图片再次展示如下: 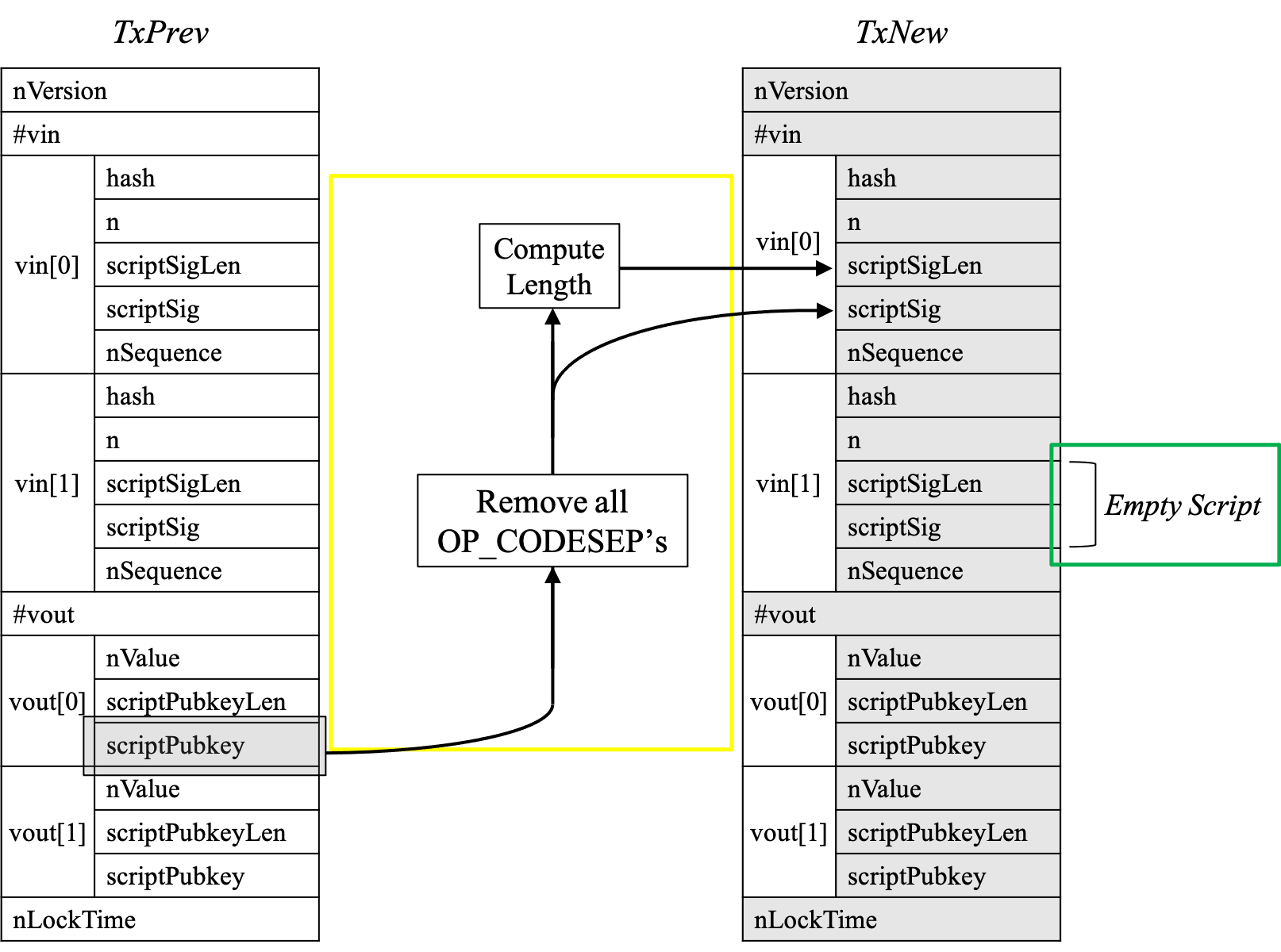 需要注意的是, L631行首先将交易(
需要注意的是, L631行首先将交易(tx)拷贝了一份,因为交易是以传址的方式传入当前函数的,当前函数并不该修改原交易。 当前函数包含一些对交易内容修改的操作,但这些操作只是为了生成message,应该在交易的拷贝(txCopy)上进行。
D. 针对无修饰类具体类型的处理
L643行到L676行分别针对具体的签名类型进行处理。 #### 1. SIGHASH_NONE类型 L644行至L650行,对SIGHASH_NONE类型的签名进行处理。 回顾上篇博客的III.A.2小节(如下图所示),所有的output都被置为空 (L645),除当前input之外的所有input的nSequence被置为0 (L648). 
2. SIGHASH_SINGLE类型
L652行至L667行,对SIGHASH_SINGLE类型的签名进行处理。 回顾上篇博客的III.A.3小节(如下图所示)。 为了只保留对应当前input的output,calcSignatureHash函数分两步进行处理:
- 首先对当前切片进行截取,只保留索引小于等于当前
input的元素 (L654行) - 对索引小于当前
input的元素,Value置为-1,PkScript置空。
也就是说,我们在上篇博客的III.A.3小节中描述得并不准确。对于索引小于当前input的元素,并没有直接删除,而是对其进行了置-1置空的处理 对于当前input之外的input,将其nSequnce置为0.
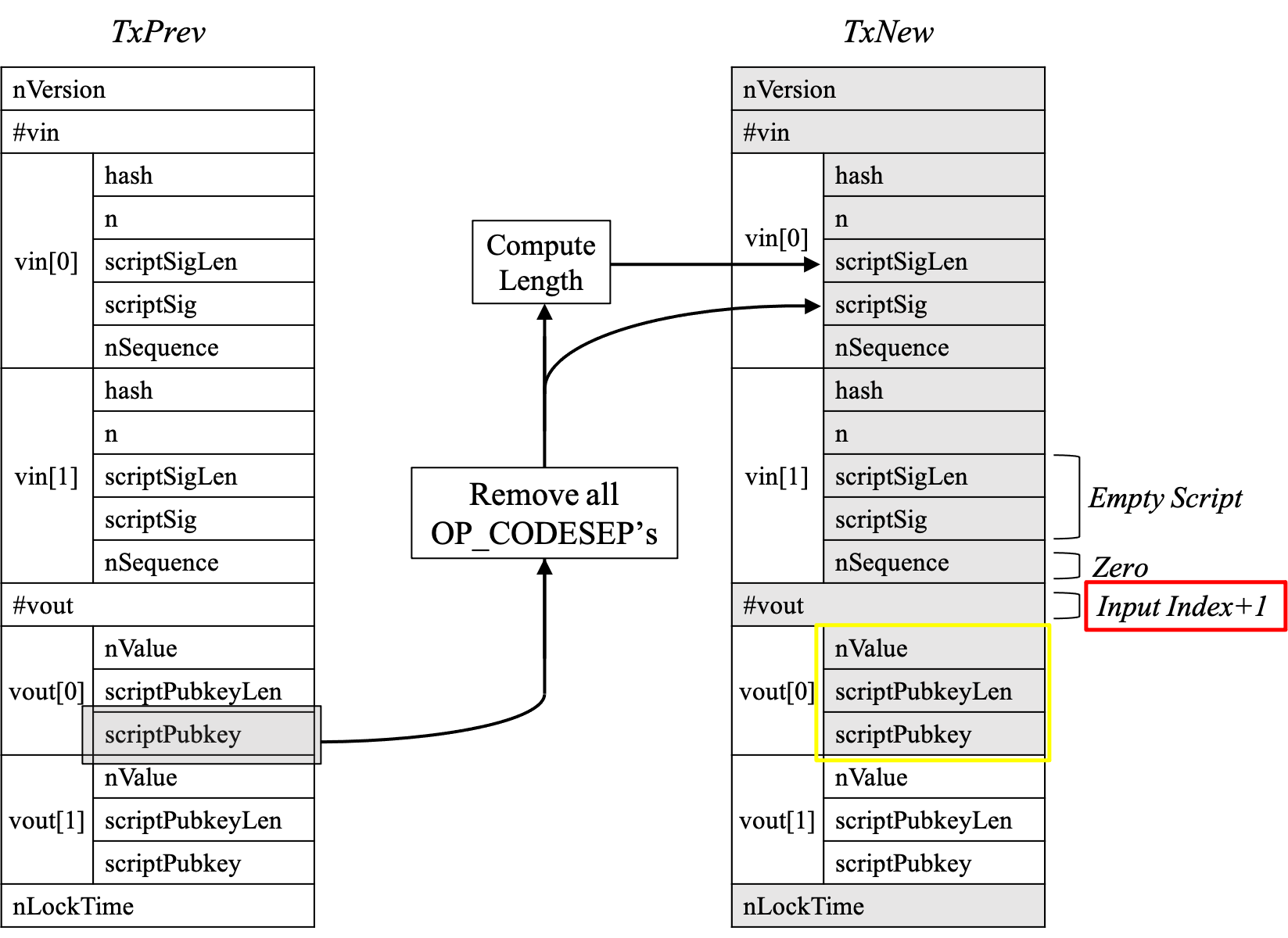
3. SIGHASH_ALL类型
L669行至L676行,对SIGHASH_ALL类型的签名进行处理。 从代码中可以看出,SIGHASH_OLD类型以及默认处理都采取了和SIGHASH_ALL一样的处理方式。 正如上篇博客的III.A.1小节中所述,SIGHASH_ALL类型签名的处理方式即是IV.C节中的input通用处理方式。因而,不需要再做额外的处理。
E. 针对有修饰类具体类型的处理
有修饰类和无修饰类最大的不同在于input的处理上。 如上篇博客的III.B小节所述,有修饰类即在无修饰类的基础上,将其他input去除。示意图片如下所示,代码如L678至L680所示。 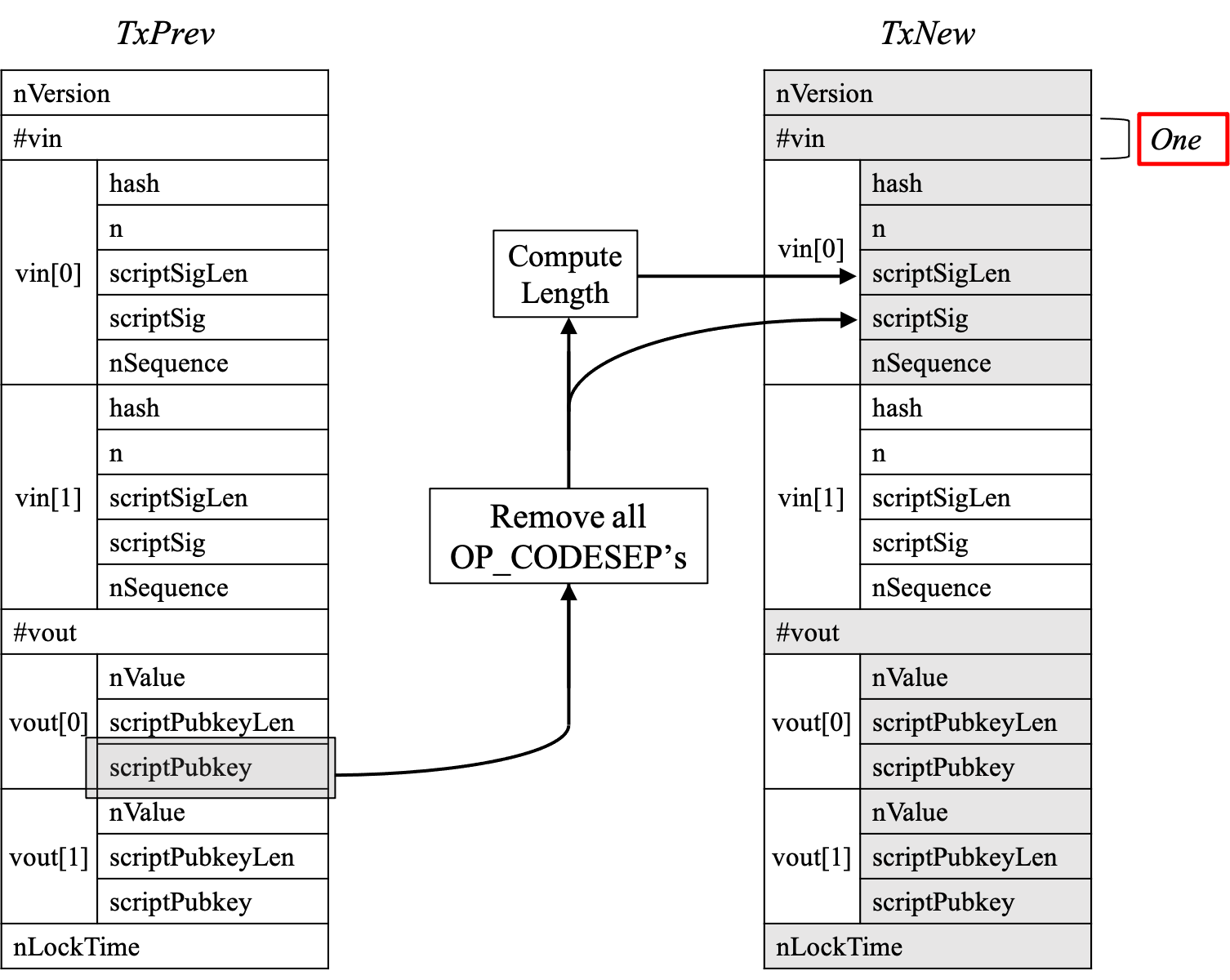
F. 生成message
基于前面步骤得到的交易副本 (txCopy),通过序列化、双哈希等方式,即可生成所需的messsage. 该部分实现如代码L685至L699行所示。